计算机网络中的流量控制与拥塞控制¶
TCP(Transmission Control Protocol)是面向连接的传输层协议,不仅具有多进程复用网络、差错校验功能,还有可靠数据传输、流量控制和拥塞控制功能。流量控制和拥塞控制都是通过控制发送方发送未被 ACK 的数据包的数量控制的。
流量控制¶
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Port | Destination Port |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Acknowledgment Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data | |U|A|P|R|S|F| |
| Offset| Reserved |R|C|S|S|Y|I| Window |
| | |G|K|H|T|N|N| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Checksum | Urgent Pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| data |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
TCP Header Format
Note that one tick mark represents one bit position.
Figure 3.这是 TCP 的报文结构,来自 RFC793,可以看到有一个 16 位的 Window 字段,RFC 中是这样解释的:
The number of data octets beginning with the one indicated in the acknowledgment field which the sender of this segment is willing to accept.
也就是说,Window 大小是接收方愿意接受的数据的大小;这个数据会有一个放大倍数,是客户端和服务协商好的,比如下边这个是 256。
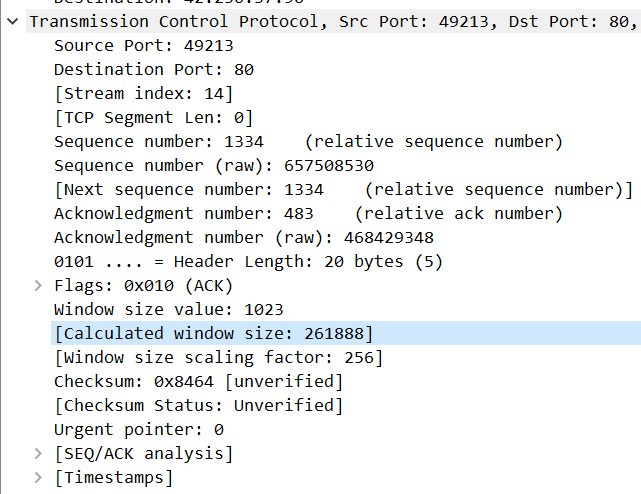
现在的问题是,如何计算自己的 Window size 呢?
TCP 是有缓冲区的,建立 TCP 连接之后,操作系统会分配缓冲区,缓冲区大小是有限的,数据的处理需要时间,中间丢包还需要暂存数据。一般来说,TCP 的一方(称其为 B)在接收时会维护两个状态:
LastByteRead:B 的应用层进程读出的最后一个字节的序号
LastByteRcvd:B 的网络层传到传输层的最后一个字节的序号
TCP 缓冲区不能溢出,所以我们规定:LastByteRcvd - LastByteRead <= RecvBuffer,注意这里的减法是\(\mod 2\)意义下的,永远都是自然数。
因此接收窗口Receive Window由公式计算得到:rwnd = RecvBuffer - [LastByteRcvd - LastByteRead]
和 B 建立连接的 A 也维护着 B 的两个状态:
LastByteSent:A 的传输层传到网络层的最后一个字节的需要
LastByteAcked:A 接收到最大的ACK的序号
在发送的时候,A 掌握着主动权,在传输的全过程中,它需要维持以下不等式成立:LastByteSent - LastByteAcked <= rwnd
有另外一个小问题:如果 B 的缓冲区满了,它送回一个 0,那么 A 怎么知道 B 的缓冲区什么时候空了呢?事实上,标准规定 A 在得知 B 的rwnd为 0 时,依然会持续发送一字节的报文,直到 B 返回的 ACK 报文中的Window size成为正值。
拥塞控制¶
网络拥塞(network congestion)是指在分组交换网络中传送分组的数目太多时,由于存储转发节点的资源有限而造成网络传输性能下降的情况。
拥塞的表现其一是路由器缓冲溢出导致的丢包——不是你丢包,就是我丢包,其二是由排队延迟造成的延迟过大。丢包的第一反应是重传,但重传应该属于“治标不治本”的下下策。解决网络拥塞的问题,最好的方法是发送方主动减少发包数量,各退一步,海阔天空。(下面我们会从例子看到为什么这么说)
小冷知识:
UNIX系统作为分时操作系统,其上的nice程序的功能是“主动让出一部分 CPU 时间片给其它用户”。实际上,没有人会主动用这个程序
拥塞的原因¶
下面用三个例子分析一下拥塞的原因
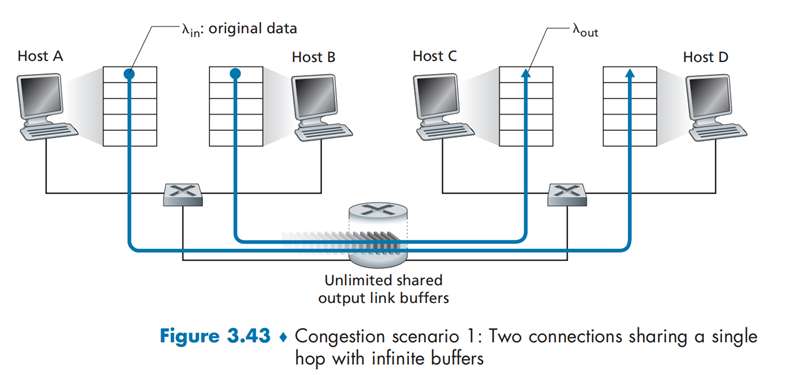
情况一:两个发送方和一台具有无穷大缓存的路由器'¶
假设
- 路由器无限缓存:不会出现分组丢失,无需重传
- 不执行流量控制或拥塞控制
- 数据链路带宽为\(R\)
- \(λ_{in}\)表示主机 A 和 B 发送的速率;\(λ_{out}\)表示主机 C 和 D 接受的速率
网络拓扑如下
当发送速率在\(0 \sim R/2\)之间,接收方的吞吐量等于发送方的吞吐量。当发送速率超过\(R/2\)时,吞吐量停止在\(R/2\),不再增长。
当\(λ_{in}\)逐渐增大时,时延也在增大。当\(λ_{in}\)靠近\(R/2\)时,时延快速增长到无穷大。
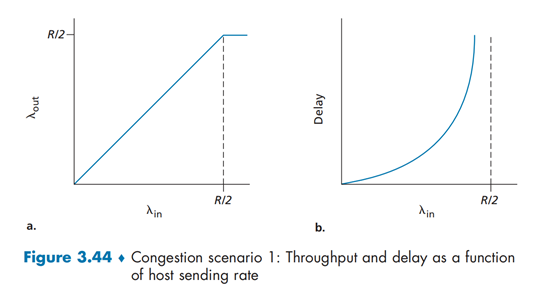
由此可以看出,拥塞带来的代价是吞吐的时延极大
情况二:两个发送方和一台具有有限缓存的路由器¶
假设:
- 路由器缓存容量有限:当缓存满时会丢包,需要重传
- 没有拥塞控制和流量控制机制
- 初始数据的发送速率为\(λ_{in}\),初始数据加重传数据的发送速率为\(λ_{in}^′\)
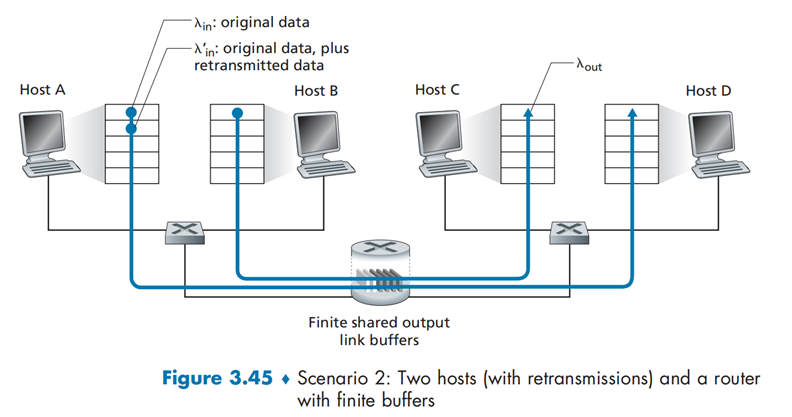
方式 a:发送方可以获取路由器的 buffer 信息(实际上不存在这种情况),当路由器 buffer 有空闲时才发送分组。在这种情况下,不会产生丢包,吞吐量就是\(λ_{in}\)。
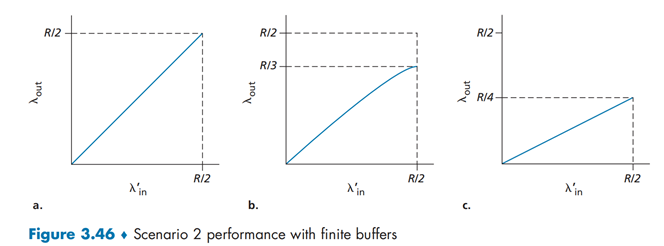
方式 b:发送方仅在丢包后重传数据,对于超时则不理会(将超时时间设定的足够长即可)。此时\(λ_{in}^′>λ_{out}\)。平均来讲,在\(R/2\)的发送数据中,\(R/3\)为初始数据,\(R/6\)为重传数据。
方式 c:分组丢失和超时后都重发,此时\(λ_{in}^′\)变得更大。此时初始数据发送的速率只有\(R/4\),重传的数据达到了\(R/4\)
(平均每个分组被路由器转发两次时,由于每个分组被转发两次,当其供给载荷接近\(R/2\)时,其吞吐量将渐近\(R/4\))
代价:需要做更多的重传,并造成资源的浪费。(重传数据需要再次使用数据链路)
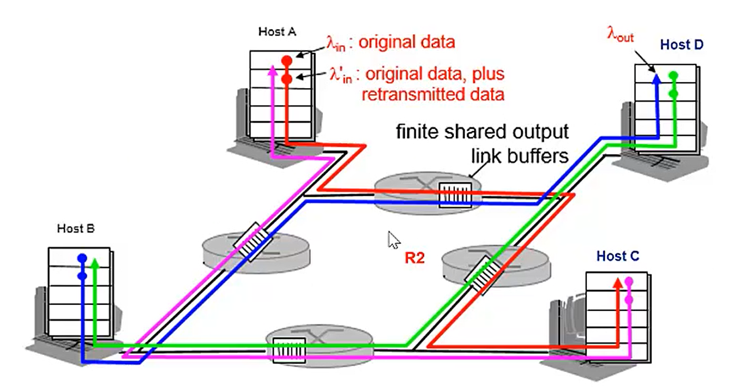
情况三:四个发送方和具有有限缓存的多台路由器及多跳路径¶
假设:
- 四台主机互相发送分组,每台都通过交叠的两条路径传输
- 每台主机都采用超时/重传机制来实现可靠数据传输服务
- 所有主机都有相同的\(λ_{in}\)值,所有路由器带宽都是\(R\)字节/秒。
- 路由器缓存有限
- \(λ_{in}\)依然表示初始数据的传送速率,\(λ_{in}^′\)表示初始数据+重传数据的传送速率
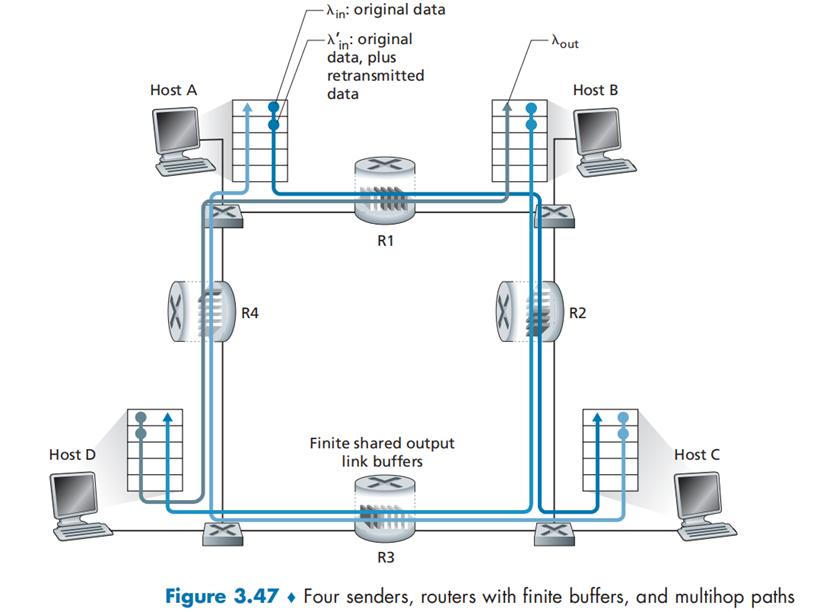
对路由器 R2 进行分析:
- A 到 C 传输最后经过 R2 路由器,而 B 到 D 传输首先经过 R2 路由器;
- A 与 B 会在路由器 R2 上发生竞争,但由于 B 先经过 R2,B 流过的速率会比 A 流过的大得多。
- 由于 A 在对路由器 R1 的抢占过程中占优,因此 R1 中的大多数据为 A 发送的数据
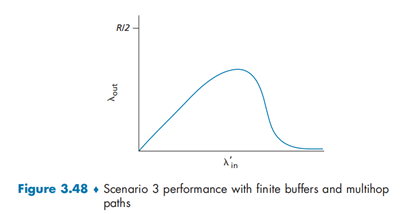
- R2 会将 A 发送的数据大量丢包,这将导致“上游“路由器存储转发的大量数据作废。这也是图中当 λ_in 增加到一定程度时,其吞吐量会显著下降的原因。
代价:共享路由器的问题,当分组被丢弃时,任何用于该分组的“上游“传输能力全部被浪费掉
When a packet is dropped along a path, the transmission capacity that was use at each of the upstream links to forward that packet to the point at which it is dropped ends up having been wasted.
TCP 拥塞控制¶
TCP 采用端到端的可靠数据传输机制(因为 IP 不提供可靠数据传输服务)。这就引出了一系列问题:
- TCP 发送方如何控制发送速度?
- TCP 发送方怎么知道网络中发生了拥塞?
- 发送方知道网络中发生了拥塞,它根据何种算法调节自身的发送速度?
上面流量控制讲到,TCP 使用一个rwnd变量控制发送方的发送速率,因此,我们也可以用同样的方式进行拥塞控制
LastByteSent - LastByteAcked <= min{cwnd, rwnd}为了聚焦于拥塞控制,我们假设rwnd无限大——至少是不会比cwnd小,因此拥塞窗口大小仅由cwnd决定;并且假定发送方一直有数据可以发送,也就是一定会填满拥塞窗口。因此,发送方每次发送cwnd个包,经过一个 RTT 后收到 ACK 又发出一个包,传输速率约为cwnd/RTT.
依赖本地知识的 TCP 的拥塞控制有三条原则:
- 一次丢包意味着网络拥塞,发送方应该降低发送速度
- 收到一个新的 ACK 说明网络状况良好,发送方应该提高发送速度
- 带宽探测机制
MSS(Maximum Segment Size)指一个报文中的数据的大小。以太网的 frame 被限制为 1500 字节,IP 头一般为 20 字节,TCP 头为 20 字节,所以在 TCP/IP 网络中的 MSS 一般是 1460,当然也可能因为网络限制而取更小的值。
RFC 2581 中详细定义了 TCP 拥塞控制算法,分为三大部分:慢启动、拥塞避免、快恢复
慢启动¶
慢启动其实不慢,甚至是指数级增长的。在 TCP 连接刚建立和每次 timeout 之后都会进入慢启动阶段。在慢启动阶段,cwnd从一个 MSS 开始,每收到一个新的 ACK,每次cwnd *= 2,直到达到快速启动阈值(Slow Start Thresh, ssthresh)。每次探测到拥塞(超时或收到三个冗余 ACK(也就是“旧的 ACK”)时,ssthresh就会将为cwnd的一半。
网络中路由器的缓冲区都是有限的,并且还有ssthresh这一个上限,所以cwnd不可能一直指数增长下去,最多达到ssthresh,进入拥塞避免阶段,或者遭遇丢包???回到快速启动的开始阶段
拥塞避免¶
经过慢启动,cwnd的大小大概是上次该连接经历丢包时cwnd的一半。该状态下,每收到一个新的 ACK,发送方的cwnd都增加 1。
快恢复¶
快恢复是指,将cwnd减半后,每收到一个冗余 ACK(没有超时,收到回复了,只是不是成功接受的回复),cwnd都增加 1。
而 timeout 后,ssthreas = cwnd/2, cwnd = 1,直接回到慢启动的最初阶段。
在 TCP 早期一个版本,TCP Tahoe 中没有快恢复,timeout 或三个冗余 ACK 都回到慢启动;而 TCP Reno 中采用了接收到冗余 ACK 后进入快速恢复阶段的策略。
小结¶
如果忽略慢启动阶段,假设没有 timeout,TCP 拥塞控制采用的是 AIMD(Additive Increase, Multiplicative Decrease)方案(锯齿状)。除了 Tahoe 和 Reno 之外,还有 Vegas 和 CUBIC 等算法;最新进展:RFC 6582 定义了 TCP NewReno 算法。
总之,TCP 拥塞控制算法是大量工程经验和实验的产物,经受住了十余年的考验,获得了理论上和时间上的成功。
拥塞控制下 TCP 的吞吐量¶
前文说过,在没有丢包的、忽略慢启动和快恢复的理想情况下 TCP 的吞吐量约为\(w/RTT\)(\(w\)位窗口大小)。假设网络情况在传输全过程中不变,最大窗口大小为\(W\)(超过就会丢包,丢包后窗口大小减半),那么显然可知
但是,在今天的网络中,在两台主机之间正在传输的数据包的数量可能数以万计——丢掉一万个包才发现丢包了吗?
因此,我们将 TCP 连接的平均吞吐量写成丢包率\(L\)的函数
根据以上公式,可以发现,为了达到 10Gbps 的速率,如今的 TCP 连接最多丢掉\(2\cdot 10^{-10}\)的包\(\frac{1}{5,000,000,000}\)。
ATM ABR 协议中的拥塞控制¶
文章主要讲解了 TCP/IP 协议。除此之外,还有在 Asynchronous Transfer Mode 网络中的 Available Bit-Rate 服务。
ATM 采用了面向虚电路(Virtual Circuit)的报文交换方式。在虚电路中,每路径上的每个交换机都维护着一个虚电路的状态,非常适合网络辅助的拥塞控制(network-assisted congestion control)。
在 ATM 中,负责转发的节点被称为 switch,数据包被称为 cell。在 switch 之间传输的不仅有 data cell,还有 resource-management cell。一般情况下是 32 个 data cell 就会有一个(be interspersed with a) RM cell。RM cell 可以在 switch 和 host 之中传播与拥塞有关的信息。RM cell 到达主机后,又被该主机发送给对方。
ATM ABR 采用基于速率(rate-based)的方法进行拥塞控制。发送方明确计算出最大速率,并按照此速率进行自我调节。此外,ABR 还提供以下三种机制来传输 switch 到 receiver 的信息:
- EFCI 位:Explicit Forward Congesting Indication,每个 data cell 中都有一位,路径上的 switch 可将此位置 1 以向目的主机和沿途的 switch 表示出现拥塞;目的主机接受并发现 EFCI 位后,向源主机发送一个 CI 位置位的 RM cell
- CI 和 NI 位:Congestion Indication bit and No Increase bit,两个位在 RM cell 中,沿途的 switch 会在轻度拥塞时将 NI 置位,重度拥塞时将 CI 置位,目的主机接收到 RM cell 会将 CI 和 NI 原样发回(除非是收到了带 EFCI 位的 data cell 而将 RM cell 的 CI 置位)
- ER 域:Explicit Rate field,每个 RM cell 有 2 字节的 ER 域,明确指出可用的最大速率,类似于 TCP 中的 Window,但 ABR 工作在网络层(和 IP 同一层)。沿途的 switch 可以降低这个速率,因此,主机收到的 RM cell 中的 ER 域将被置为网络中 switch 支持的速率中最小的那个。
另外,ATM 还提供 Constant Bit-Rate 服务