Basic developing
初级应用开发¶
认识任务:手写数字识别¶
深度学习模型¶
认识模型¶
这次我们用到的模型依然是经典永流传的LeNet-5。
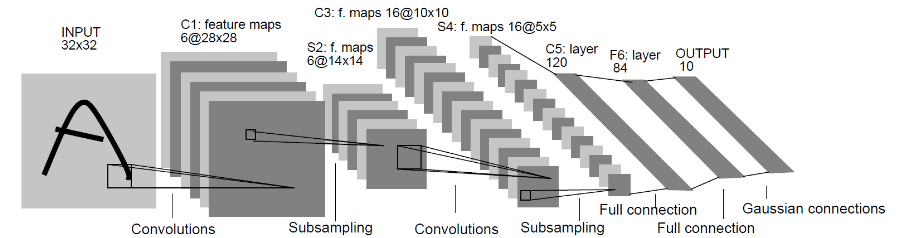
图片来源于http://yann.lecun.com/exdb/publis/pdf/lecun-01a.pdf
损失函数采用交叉熵损失函数,算法为带动量的SGD。
\[
\ell(x_i, c) = - \log\left(\frac{\exp(x_i[c])}{\sum_j \exp(x_i[j])}\right)
= -x_i[c] + \log\left(\sum_j \exp(x_i[j])\right)
\]
编写模型代码¶
编写代码部分,我们将接触昇腾工具链的第一个工具:MindSpore。
class LeNet5(nn.Cell):
def __init__(self):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5, stride=1, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, stride=1, pad_mode='valid')
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
self.fc1 = nn.Dense(400, 120)
self.fc2 = nn.Dense(120, 84)
self.fc3 = nn.Dense(84, 10)
def construct(self, x):
x = self.relu(self.conv1(x))
x = self.pool(x)
x = self.relu(self.conv2(x))
x = self.pool(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x配置运行环境¶
import os
# os.environ['DEVICE_ID'] = '0'
import mindspore as ms
import mindspore.context as context
import mindspore.dataset.transforms.c_transforms as C
import mindspore.dataset.vision.c_transforms as CV
from mindspore import nn
from mindspore.train import Model
from mindspore.train.callback import LossMonitor
context.set_context(mode=context.GRAPH_MODE, device_target='CPU') # Ascend, CPU, GPU获取数据¶
def create_dataset(data_dir, training=True, batch_size=32, resize=(32, 32),
rescale=1/(255*0.3081), shift=-0.1307/0.3081, buffer_size=64):
data_train = os.path.join(data_dir, 'train') # train set
data_test = os.path.join(data_dir, 'test') # test set
ds = ms.dataset.MnistDataset(data_train if training else data_test)
ds = ds.map(input_columns=["image"], operations=[CV.Resize(resize), CV.Rescale(rescale, shift), CV.HWC2CHW()])
ds = ds.map(input_columns=["label"], operations=C.TypeCast(ms.int32))
# When `dataset_sink_mode=True` on Ascend, append `ds = ds.repeat(num_epochs) to the end
ds = ds.shuffle(buffer_size=buffer_size).batch(batch_size, drop_remainder=True)
return ds从中获取几张数据进行可视化。
import matplotlib.pyplot as plt
ds = create_dataset('MNIST', training=False)
data = ds.create_dict_iterator(output_numpy=True).get_next()
images = data['image']
labels = data['label']
for i in range(1, 5):
plt.subplot(2, 2, i)
plt.imshow(images[i][0])
plt.title('Number: %s' % labels[i])
plt.xticks([])
plt.show()训练¶
def train(data_dir, lr=0.01, momentum=0.9, num_epochs=3):
ds_train = create_dataset(data_dir)
ds_eval = create_dataset(data_dir, training=False)
net = LeNet5()
loss = nn.loss.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
opt = nn.Momentum(net.trainable_params(), lr, momentum)
loss_cb = LossMonitor(per_print_times=ds_train.get_dataset_size())
model = Model(net, loss, opt, metrics={'acc', 'loss'})
# dataset_sink_mode can be True when using Ascend
model.train(num_epochs, ds_train, callbacks=[loss_cb], dataset_sink_mode=False)
metrics = model.eval(ds_eval, dataset_sink_mode=False)
print('Metrics:', metrics)
train('MNIST/')导出模型¶
input_spec = Tensor(np.ones([1, 1, 32, 32]).astype(np.float32))
ms.export(model, mindspore.Tensor(input_spec), file_name='lenet', file_format='ONNX')模型转换¶
做到上一步之后,我们已经有了lenet.onnx文件,下面的操作我们将在设备端进行。
在上一步我们进行了模型导出。
模型导出与Checkpoint saving有什么不同呢?
Checkpoint是研究中用到的,通过save_checkpoint与load_checkpoint进行交互;Checkpoint本质上可以看成是一个Python的dict。比如上述LeNet的一个Checkpoint:
{
'conv1.weight': Parameter (name=conv1.weight, shape=(6, 1, 5, 5), dtype=Float32, requires_grad=True),
'conv2.weight': Parameter (name=conv2.weight, shape=(16, 6, 5, 5), dtype=Float32, requires_grad=True),
'fc1.weight': Parameter (name=fc1.weight, shape=(120, 400), dtype=Float32, requires_grad=True),
'fc1.bias': Parameter (name=fc1.bias, shape=(120,), dtype=Float32, requires_grad=True),
'fc2.weight': Parameter (name=fc2.weight, shape=(84,
120), dtype=Float32, requires_grad=True),
'fc2.bias': Parameter (name=fc2.bias, shape=(84,), dtype=Float32, requires_grad=True),
'fc3.weight': Parameter (name=fc3.weight, shape=(10,
84), dtype=Float32, requires_grad=True),
'fc3.bias': Parameter (name=fc3.bias, shape=(10,), dtype=Float32, requires_grad=True)
}而导出模型则是将模型编译,编译后的模型可以脱离Python语言环境,在专用的运行时中执行,效率也更高。类似于Java代码编译为字节码之后在JVM中执行。
编译模型使用的工具是 Ascend Tensor Compiler,这是我们学到的昇腾工具链中第二个工具。这个工具属于 CANN 的一部分。
原理¶
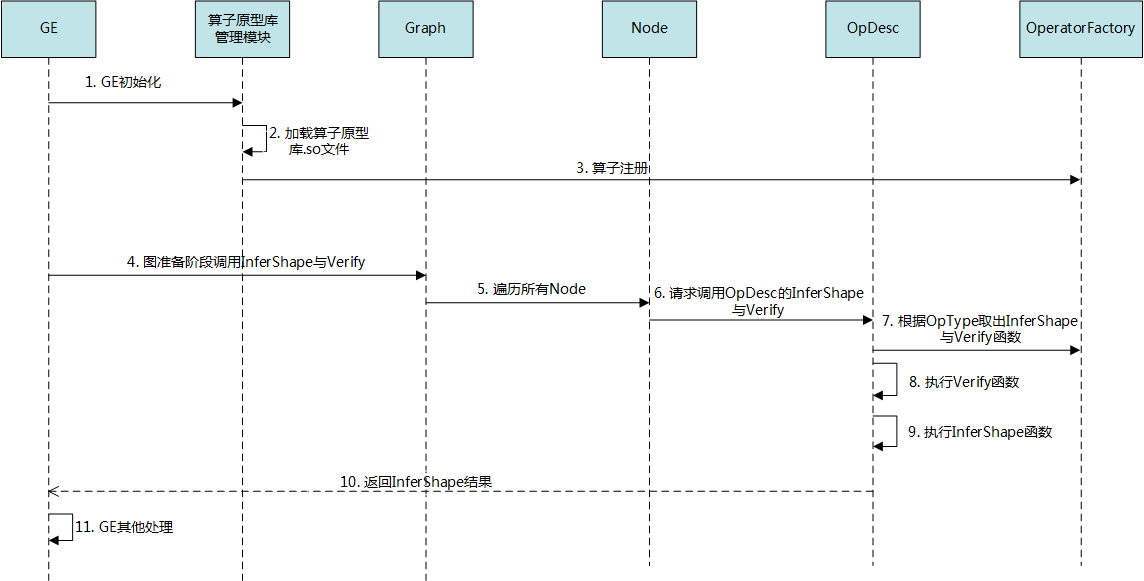
atc --mode=0 --framework=5 --model=lenet.onnx --output=onnx_lenet --soc_version=Ascend310https://support.huaweicloud.com/atctool-cann51RC1alpha1/atlasatc_16_0001.html

设备端部署与测试¶
最后更新:
2023-01-31