Swin Transformer
各位小伙伴们,大家下午好。下周四(2021 年 11 月 26 日)我将进行研读论文的题目是《Res2Net: A New Multi-Scale Backbone Architecture》和《Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows》,论文 PDF 已上传至群文件,请感兴趣的小伙伴自行查阅。
http://scuvis.org/2021autumnpaper-1202/
@InProceedings{Liu_2021_ICCV,
author = {Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
title = {Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {10012-10022}
}Transformer 是在自然语言处理领域大获成功的 RNN 模型,并且在计算机视觉任务中也表现出优异的成绩。但是,相较于文本,视觉实体的尺度变化更大、分辨率更高等特点,都给 Transformer 的在计算机视觉上的应用带来了挑战。为了解决此问题,作者提出了一种层级化的 Transformer 网络,并使用 Shifted Windows 方法进行 representation 的计算。Shifted Windows(简称 Swin)方法将自注意力的计算限制在不重叠的局部窗口中,通过 shifted window 方法实现跨窗口信息连接。网络的层级化结构使得网络能够适应多种尺度的视觉目标,并且 Swin 的计算只有线性时间复杂度。以 Swin Transformer 作为骨干网络的模型在多个计算机视觉任务中取得了 SOTA 的成绩。
背景引入¶
研究动机
to expand the applicability of Transformer such that it can serve as a general-purpose backbone for computer vision, as it does for NLP and as CNNs do in vision.
相较于 CV 界各种维度、各种残差连接、各种计算层(研究结构、研究单层(depth wise convolution [70] and deformable convolution [18, 84].))的卷积神经网络百花齐放,NLP 界的 Transformer 一枝独秀。Transformer 具有强大的学习数据中长期依赖的能力,在以往的研究中,将 Transformer 迁移到计算机视觉领域取得了成功,但在 CV 任务上完全发挥 Transformer 的能力有很大挑战,主要有两点:1. 在 NLP 中,文字的 token 即为实体的最小元素;而在 CV 中,一个实体可以由几个到几万个像素表达;2. 在基于 Transformer 的模型中,token 的大小处于固定不变的尺度,但在 CV 中不是如此,甚至在场景分割等任务中需要预测每一个像素点所属类别,Transformer 计算量过大而不可行。
Transformer¶
要理解文中的 Swin Transformer,需要先了解 Transformer 和 Vision Transformer。
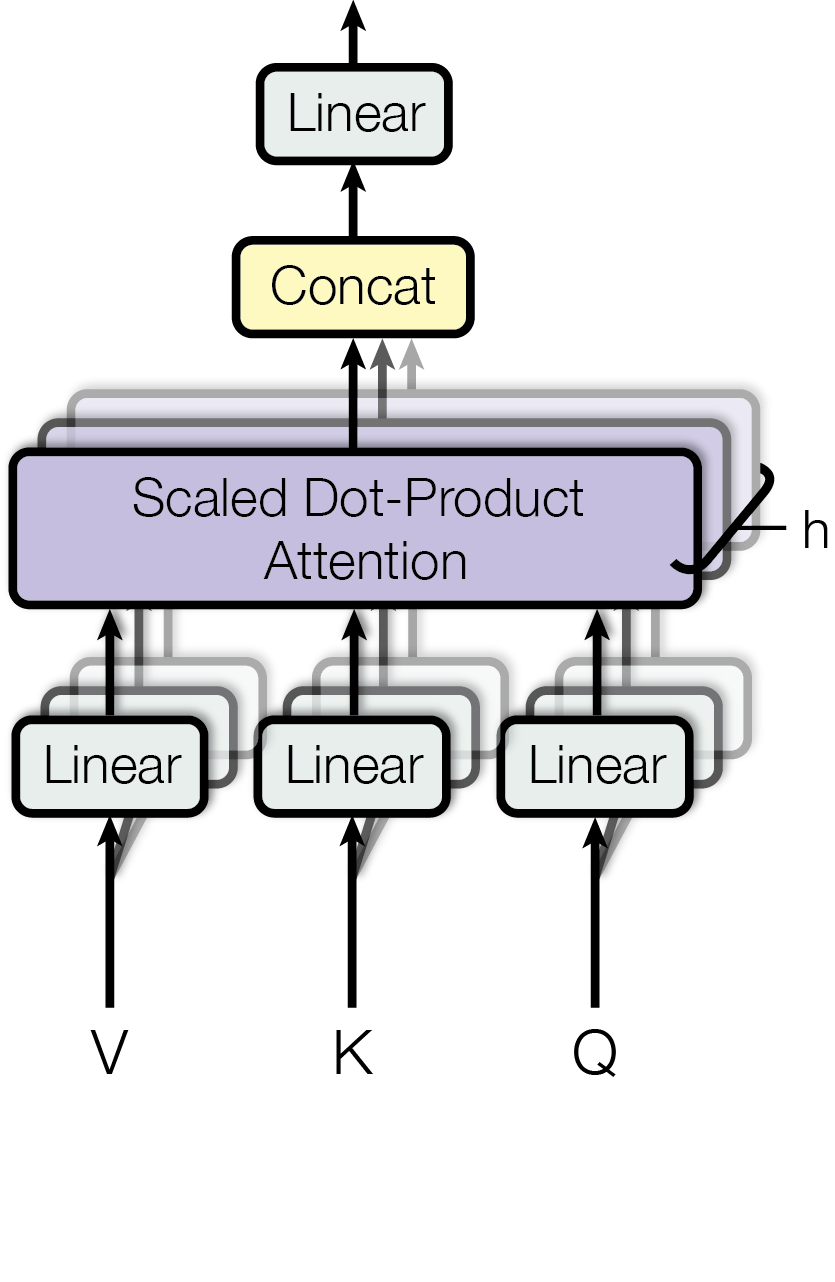
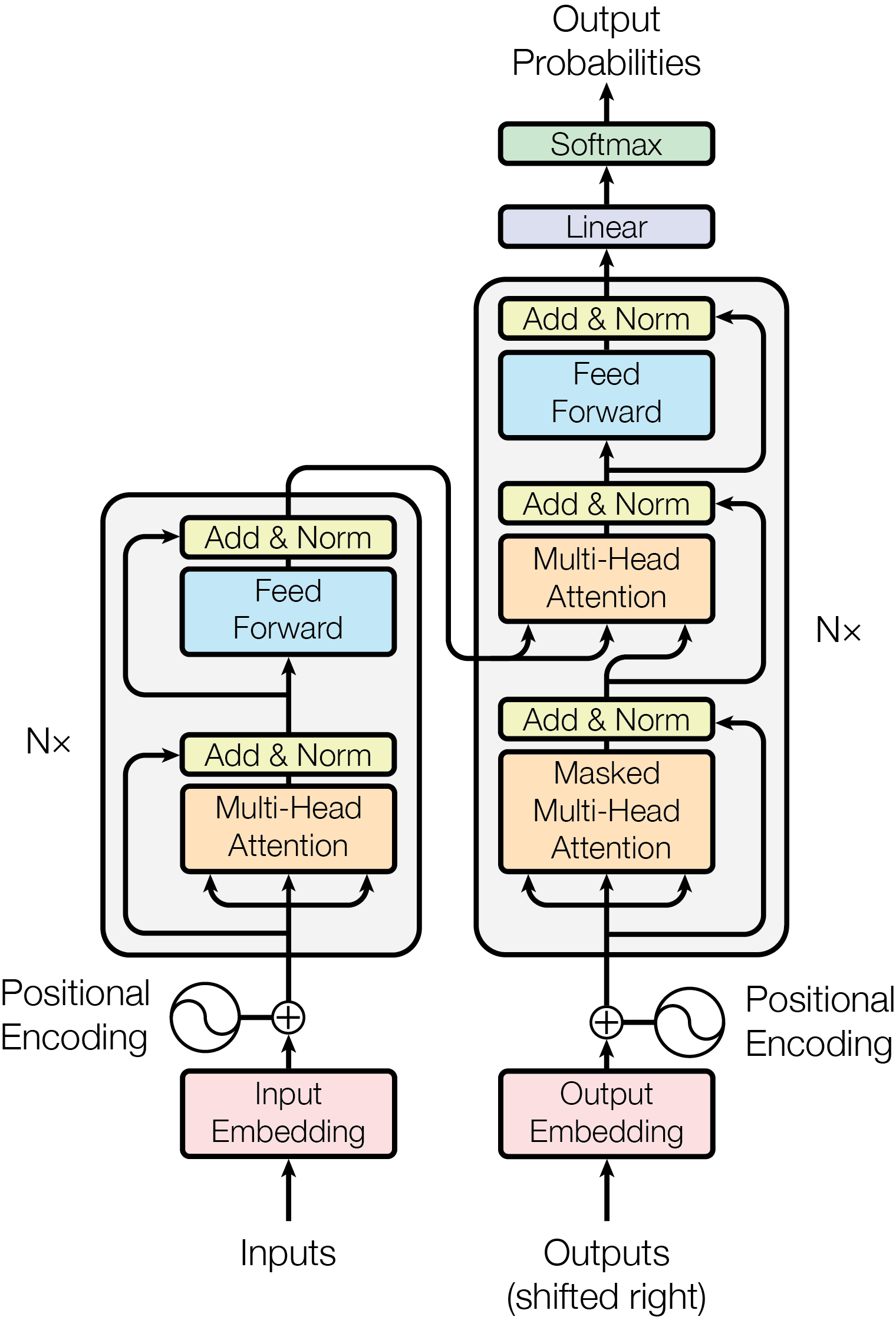
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 2017-December.
Self-attention based¶
卷积神经网络的本质是特征提取,但卷积并不是最好的特征提取器(其实没有最好),一定程度上因为卷积核大小固定,难以提取图像的多尺度信息
在 2019 年微软亚洲研究研究院的 LR-Net,在 26 层的 LR-Net 超过 26 层的 ResNet 3 个百分点
H. Hu, Z. Zhang, Z. Xie and S. Lin, "Local Relation Networks for Image Recognition," 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 3463-3472, doi: 10.1109/ICCV.2019.00356.
滑动窗口访问内存的随机性导致计算性能并不好
Transformers to complement CNNs¶
ViT & ResNe(X)t¶
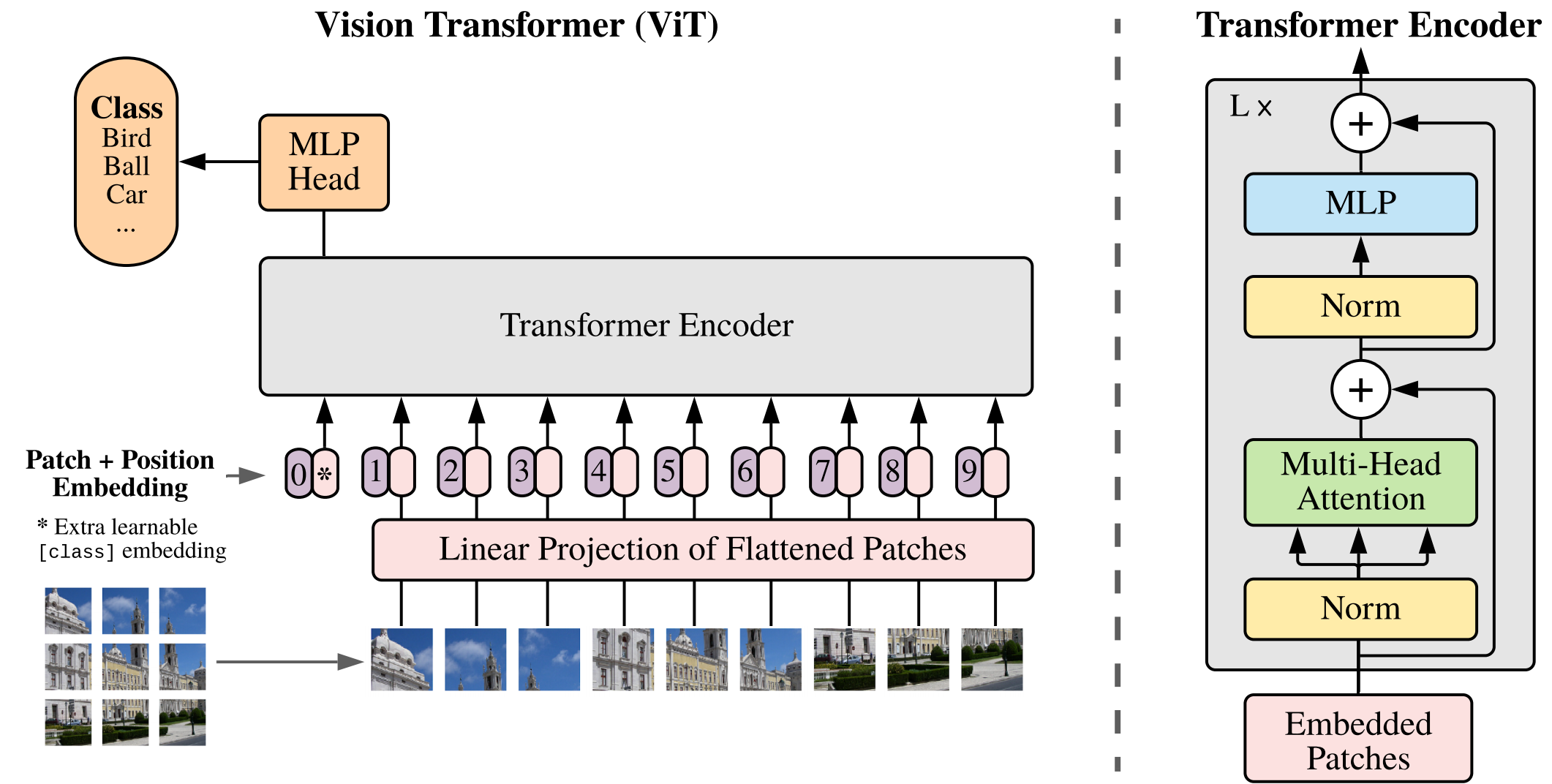
Is, M., For, R., & At, E. (2021). An image is worth 16x16 words. The International Conference on Learning Representations.
Vision Transformer 将图像分割成小 patch,将每个 patch 当成 Transformer encoder 中的输入序列,达到了极佳的速度-精度平衡。ViT 通常需要很大的数据集(JFT-300M)才能达到比较好的效果。
但是,ViT 并不适合用作 general purpose backbone,因为图像都是稠密的,当输入图像分辨率很高时,每个 patch 得到的信息将会变少,同时在\(O(n^2)\)(\(n\)为图像大小)复杂度下算力消耗大。
虽然 Swin Transformer 不一定是最能刷榜的,但是是最有思想的。
Xie, S., Girshick, R., Dollár, P., Tu, Z., & He, K. (2017). Aggregated residual transformations for deep neural networks. In Proceedings - 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017 (Vol. 2017-January, pp. 5987–5995). Institute of Electrical and Electronics Engineers Inc. https://doi.org/10.1109/CVPR.2017.634
To overcome…¶
hierachical feature maps => conveniently leverage advanced techniques for dense predicion such as FPN or U-Net
shifted windows
linear complexity to image size <= The numbers of patches in each window is fixed (previous: quadratic)
Method¶
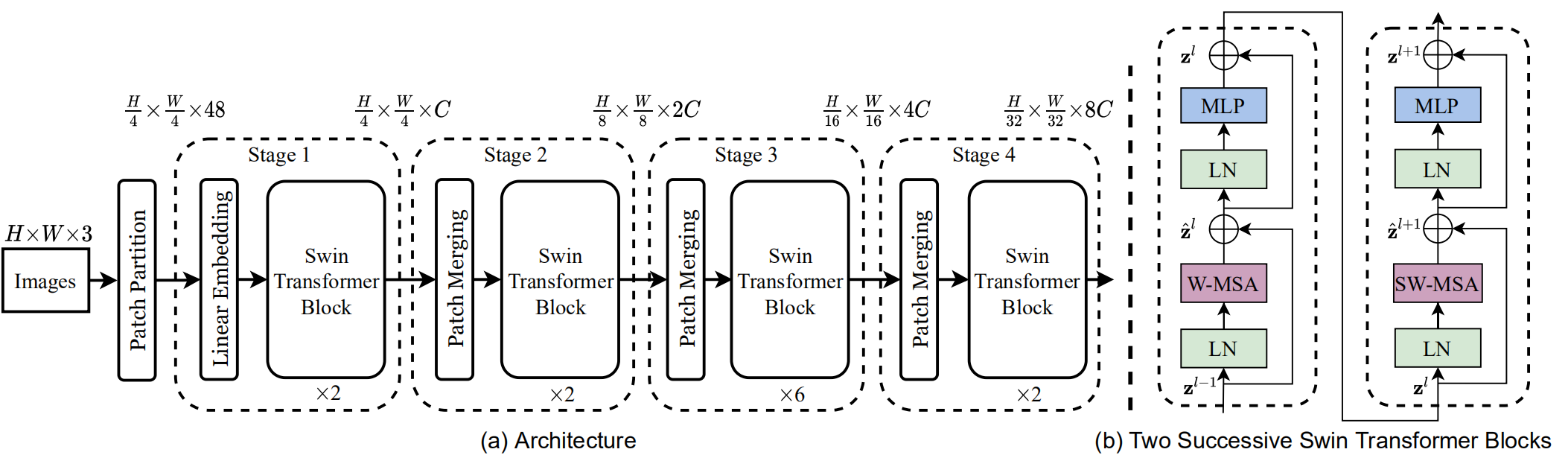
Swin Transformer Tiny 结构如(a),选取\(4\times4\)大小的 patch(3 个通道,一共 48 个像素),Linear Embedding(是个全连接层吗?看代码)将 patch 投影成一个\(C\)维向量。Stage 1 的 Swin Transformer Block 维护一定数量的\(\left(\frac H4 \times \frac W4\right)\)的 token。
为了得到层级式的表达,token 的数目在每两个 Swin Transformer Block 之间会经过 Patch Merging 减到原来的\(1/4\),也就是\(2\times 2\)的 patch 会被融合成一个\(4C\)大小的向量,然后经过一个全连接(linear layer),输出维度为\(2C\)的向量。Stage 2 的 Swin Transformer Block 的分辨率就是\(\left(\frac H8 \times \frac W8\right)\);Stage 3 和 4 与 2 相同,所以他们的输出分别是\(\left(\frac H{16} \times \frac W{16}\right)\)和\(\left(\frac H{32} \times \frac W{32}\right)\)。该网络可以和 ResNet、VGGNet 产生相同分辨率的 feature map,可以方便地替换之而成为新的 backbone。
介绍了 Swin Transformer 之后,我们介绍其中最重要的,Swin Transformer Block。STB 将传统 Attention 机制中的多头自注意力模块换成了 Shifted Window 模块。在(b)中,STB 包括一个 LayerNorm 块,一个基于多头自注意力机制的 Swin 块,又一个 LayerNorm 块,最后一个两层的、中间一个 GELU 激活函数的多层感知机。
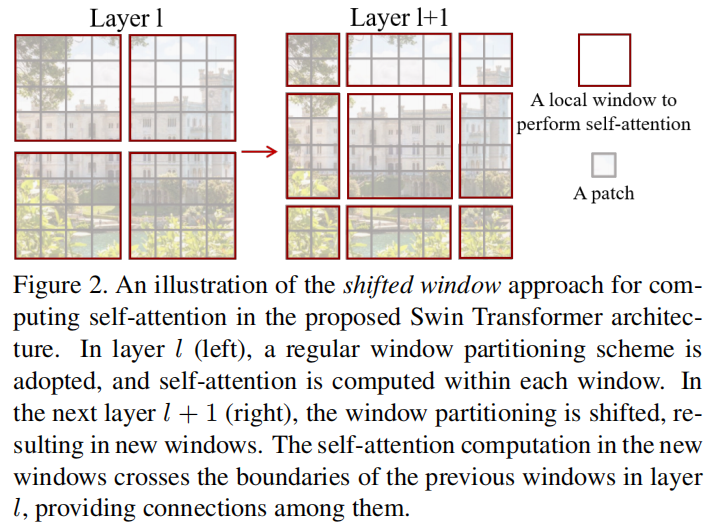
key design¶
理解这个shifted,注意用的是 shifted 而不是 sliding 或 shifting,是现在完成时而不是进行时,所以在神经网络训练过程中是不会出现 shift 这个操作的,这个我最开始也没想明白。
all query patches within a window share the same key set1 ,
计算复杂度问题¶
对于将图像用于 Transformer 来说,由于 Transformer 处理的是序列。如果要处理一张\(H\times W\)的图像,需要将图像当成序列输入,将图像切分为\(h \times w\)的 patch,MSA 的时间复杂度可以表示为
而如果将图像划分为若干个 patch,每个 window 中有\(M\times M\)个 patch,这种 Window-MSA 的时间复杂度为
MSA 对\(hw\)是平方级,而 W-MSA 对\(hw\)是线性级,这就很好地处理了随着图像分辨率的提高造成的计算复杂度快速上升的问题。
提问:它对\(M\)不是平方级的吗?\(M\)不会增大吗?
Shifted Windows¶
在单个 Window-based self-attention 模块中没有跨 Window 的连接。
下一块中,作者对 window 进行了\(\left(\lfloor\frac M 2\rfloor, \lfloor\frac M 2 \rfloor\right)\)的位移(displace)。
所以,连续两层的 Swin transformer 的计算可以如下表示:
\(\hat{\mathbf z}^l\)指第\(l\)层(S)W-MSA 输出的特征向量,\(\hat{\mathbf z}^l\)指第\(l+1\)层 MLP 输出的特征向量
但是可以看到,Shifted window 会产生更多的 window,也就是周围一圈大小小于\(M\times M\)的 window,故采用 cylic shifting,也就是,循环移位,也就是,一个 window 里有好多 sub-window,然后在 self-attention 计算的时候将 sub-window 使用 mask 提取出来。
相对偏置¶
在计算自注意力时,相较于原方法,在每个头上加了一个 relative position embedding 的偏置\(B \in \mathbb{R}^{M^2\times M^2}\)的偏置,修正后的公式如下:
\(d\)是query/key dimension
结构变种¶
上文介绍主要基于 Swin Transformer Tiny,还有 Small,Big,Large 等大小。(移动端的,PC 端的,服务器端的,用来刷榜的)
实验结果¶
在各数据集上的测试、与 ViT、ResNeXt 的对比、消融实验(Ablation study),略
总结¶
代码解读可参考:https://zhuanlan.zhihu.com/p/401661320
Marr Prize