02
神经网络主要由两方面组成,一个打分函数输入数据映射到类分数,一个损失函数用于考量打分结果与真实结果的“距离”。之后的故事就是一个优化问题,即调节打分函数的参数,最小化损失函数的输出。
打分函数¶
假定我们有一个数据集\(\{x_i | x_i \in R^D\}\),每张图片\(x_i\)对应一个标签\(y_i\),\(i=1\ldots N\),\(y_i \in 1\ldots K\),\(D\)为输入图像的维度。打分函数\(f: R^{D} \mapsto R^{K}\)定义如下:
线性打分函数¶
最简单的打分函数莫过于线性函数
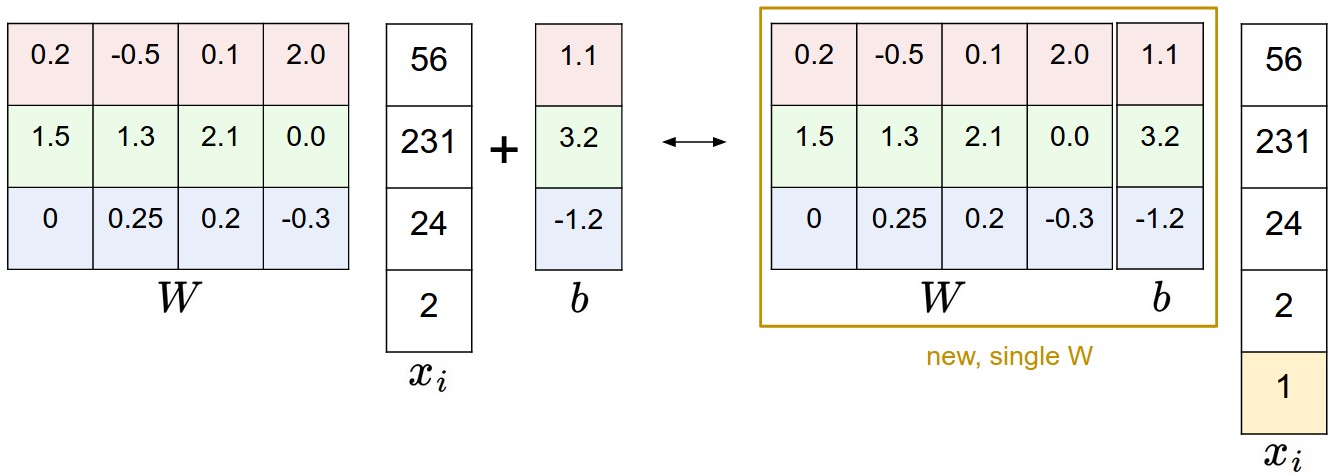
其中,\(W \in R^{K\times D}\)为权值,\(b \in R^{K \times 1}\)为偏置向量
线性打分函数输出一个\(K\times 1\)的向量,向量中每一个元素即为打分函数对该类别的打分。; {loading=lazy}
{loading=lazy}
从数学上理解,线性分类器的之所以称为”线性“,是因为分类的原理是高维空间中的线性规划问题。以CIFAR-10·数据集为例,我们是在\(32\times32\times3 = 3072\)维空间中对点进行线性分类。
Template Matching¶
从可视化结果来看,线性分类器学习到了一定的特征,虽然 horse 一类里的马好像有两个头……
 {loading=lazy}
{loading=lazy}
还有就是,一次卷积可以去掉加法,或者说,把加法融合到乘法里,充分利用了 GPU,提高了数据并行性。
 {loading=lazy}
{loading=lazy}
图像预处理¶
现在的数字图像一般都是 RGB 图像,每个图像的值在\([0, 255]\)范围内。在神经网络中通常的做法是减去均值、除以方差,将输入特征规范化到\([-1, 1]\),这对神经网络的训练是有利的。
损失函数¶
损失函数的本意不复杂:惩罚错误。
Multiclass Support Vector Machine loss¶
多目标支持向量机损失
其中,\(y_i\)是正确的类别。也就是说,当\(j \neq y_i\)时,如果\(s_j > s_{y_i}-\Delta\),那么\(L_i = s_{j}-s_{y_{i}}+\Delta\)。
当我们使用线性打分函数时,损失函数可以以向量的形式表达:
以\(\max(0, -)\)形式表述的损失函数成为脊损失函数(hinge loss)。
正则化¶
以上样例中,假定权值\(W\)可以准确地分类每一类(即每一类的损失函数值都是\(0\))。那么,\(\lambda W(\text{where}\ \lambda>1)\)同样可以正确分类,如果这样,\(W\)可以无穷无尽地变大。
所以为了抑制这种现象,我们在损失函数里增加正则化罚函数
Softmax classifier¶
cross-entropy loss
交叉熵损失涉及信息论的知识,名字里的“熵”就来自于信息论中的“信息熵”。
总之,它会输出一个向量,向量中所有元素之和为 1,也就是说,向量的每个分量可以看做该打分函数认为此图片属于该类的概率。
实际应用中,SVM 和 Softmax 基本可比。