最近做了一些关于 Vision Transformer 和 MLP 的调研,记录如下
An Image Is Worth A Thousand Words¶
书接上回,Transformer 横空出世,一举成为 NLP 领域的最佳模型,不仅在各项任务上有了突破性进展, 还催生了 BERT、GPT 等大模型。就像有人想把 CNN 搬到文本上一样,有很多工作尝试将自注意力机制与卷积融合起来。但为什么这么具有开创性意义又直截了当的工作早没有人做呢?因为他们没有 Google 这样庞大的算力。
作者实验性地将 Transformer 结构作尽可能小的改动,将图像分成\(16\times 16\)的小块,经过可学习的Linear Projection(其实就是nn.Linear),就成为了 Multihead Self-Attention 的输入 Token。使用 JFT-300M 数据集在 TPU 上训练 2.5k 核日之后在 ImageNet 上达到了\(88.55\pm0.04 \%\)的结果,成功地证明了训练 ViT 需要消耗极大的算力。
ViT核心代码如下:(参考:https://github.com/facebookresearch/dino/blob/main/vision_transformer.py
# 略去关于PyTorch的import
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, return_attention=False):
y, attn = self.attn(self.norm1(x))
if return_attention:
return attn
x = x + self.drop_path(y)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
num_patches = (img_size // patch_size) * (img_size // patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class VisionTransformer(nn.Module):
""" Vision Transformer """
def __init__(self, img_size=[224], patch_size=16, in_chans=3, num_classes=0, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., norm_layer=nn.LayerNorm, **kwargs):
super().__init__()
self.num_features = self.embed_dim = embed_dim
self.patch_embed = PatchEmbed(
img_size=img_size[0], patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
# Classifier head
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def interpolate_pos_encoding(self, x, w, h):
npatch = x.shape[1] - 1
N = self.pos_embed.shape[1] - 1
if npatch == N and w == h:
return self.pos_embed
class_pos_embed = self.pos_embed[:, 0]
patch_pos_embed = self.pos_embed[:, 1:]
dim = x.shape[-1]
w0 = w // self.patch_embed.patch_size
h0 = h // self.patch_embed.patch_size
# we add a small number to avoid floating point error in the interpolation
# see discussion at https://github.com/facebookresearch/dino/issues/8
w0, h0 = w0 + 0.1, h0 + 0.1
patch_pos_embed = nn.functional.interpolate(
patch_pos_embed.reshape(1, int(math.sqrt(N)), int(math.sqrt(N)), dim).permute(0, 3, 1, 2),
scale_factor=(w0 / math.sqrt(N), h0 / math.sqrt(N)),
mode='bicubic',
)
assert int(w0) == patch_pos_embed.shape[-2] and int(h0) == patch_pos_embed.shape[-1]
patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
return torch.cat((class_pos_embed.unsqueeze(0), patch_pos_embed), dim=1)
def prepare_tokens(self, x):
B, nc, w, h = x.shape
x = self.patch_embed(x) # patch linear embedding
# add the [CLS] token to the embed patch tokens
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
# add positional encoding to each token
x = x + self.interpolate_pos_encoding(x, w, h)
return self.pos_drop(x)
def forward(self, x):
x = self.prepare_tokens(x)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x[:, 0]
def get_last_selfattention(self, x):
x = self.prepare_tokens(x)
for i, blk in enumerate(self.blocks):
if i < len(self.blocks) - 1:
x = blk(x)
else:
# return attention of the last block
return blk(x, return_attention=True)
def get_intermediate_layers(self, x, n=1):
x = self.prepare_tokens(x)
# we return the output tokens from the `n` last blocks
output = []
for i, blk in enumerate(self.blocks):
x = blk(x)
if len(self.blocks) - i <= n:
output.append(self.norm(x))
return output但随后的研究发现,Transformer 中只关注了是丢失了translation invariance和local invariance性质的,各路研究者对 ViT 展开了多方面的改进。
Vision Transformer 中还有一个 Class Token 和 Fixing the positional encoding across resolutions 稍后再补
Date Efficient Vision Transformer 是一种知识蒸馏方法,采用一个强视觉分类器作为教师模型,使用一个 transformer 来 exploit~(剥削)~教师模型,因为暂时不研究知识蒸馏所以先放过。
书归正传,Transformer 不具有局部性,因为整个模型结构都是对图像的全局进行学习,并且对 image tokens 也没有顺序的要求。T2T ViT 尝试使用合并多个 Tokens 为一个的方式来层次化学习;CSWin Transformer 使用了十字窗口提取 patch(与十字卷积有异曲同工之处),Pyramid Vision Transformer 采用类似于特征金字塔的方式学习多尺度的特征,SWin Transformer 使用了 Shifted Window 学习局部特征,等等。
同时,也有研究者探索如何继续扩大 Transformer,所以有了 ViT-G[TODO]、DeepViT;其中 DeepViT 通过 Re-Attention,将多个头的输出再次融合,可以融合多种特征
在 ViT 发展正盛之时,有人对 Self-Attention 机制表示怀疑,并认为 ViT 带来的提升不是因为 Self-Attention 而是因为 patch;因而提出了 MLP-Mixer 等结构。Mixer 的一层十分类似于 Transformer 的一层。Transformer block 的结构是 MSA-Norm-FF-Norm,而 Mixer 是 LayerNorm-Token Mixing-LayerNorm-Channel Mixing。和 Transformer 类似的是,Mixer 在小规模的数据集上同样会严重 overfit。
与 Mixer 同期的工作还有 ResMLP,二者思想十分接近,只是 ResMLP[TODO: 增加 Mixer 与 ResMLP 的公式]使用了一个仿射变换;相较于 Mixer~土豪地~使用大量数据进行训练,ResMLP;同时 ResMLP 使用了 DINO 方法进行了自监督学习。在 ImageNet 上不预训练 69.2,ImageNet-21K 预训练 84.4
在广泛地探索新的模型的同时,还有一些研究者进行着对现有模型性质的深入探究。
著名代码库¶
rwightman/pytorch-image-modelsRoss Wightman 维护的timm库,收录了各流派的视觉模型
openmmlabOpen 喵喵 Lab,各视觉任务的模型数量众多
huggingface/transformers新兴 AI 企业:hugs:huggingface 的 transformer 库,不仅收录了用于 NLP 的 transformer,还收录了多种ViT甚至ConvNeXt,详细列表。\cite{wolf-etal-2020-transformers}
liuruiyang98/Jittor-MLP多种 MLP 算法的Pytorch和/或Jittor实现,内附一篇综述\cite{liu2021we}。
facebookresearch/dino DINO 算法以及 Vision Transformer 等。
lucidrains/vit-pytorch 又一个 Vision Transformer 库
@article{DosovitskiyAlexey2020AIiW,
abstract = {While the Transformer architecture has become the de-facto standard for
natural language processing tasks, its applications to computer vision remain
limited. In vision, attention is either applied in conjunction with
convolutional networks, or used to replace certain components of convolutional
networks while keeping their overall structure in place. We show that this
reliance on CNNs is not necessary and a pure transformer applied directly to
sequences of image patches can perform very well on image classification tasks.
When pre-trained on large amounts of data and transferred to multiple mid-sized
or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision
Transformer (ViT) attains excellent results compared to state-of-the-art
convolutional networks while requiring substantially fewer computational
resources to train.},
year = {2020},
title = {An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
copyright = {http://arxiv.org/licenses/nonexclusive-distrib/1.0},
language = {eng},
author = {Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
}@article{liu2021we,
title={Are we ready for a new paradigm shift? A Survey on Visual Deep MLP},
author={Liu, Ruiyang and Li, Yinghui and Liang, Dun and Tao, Linmi and Hu, Shimin and Zheng, Hai-Tao},
journal={arXiv preprint arXiv:2111.04060},
year={2021}
}@inproceedings{wolf-etal-2020-transformers,
title = "Transformers: State-of-the-Art Natural Language Processing",
author = "Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin Lhoest and Alexander M. Rush",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = oct,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-demos.6",
pages = "38--45"
}在视觉任务中使用 Transformer 有若干理由:
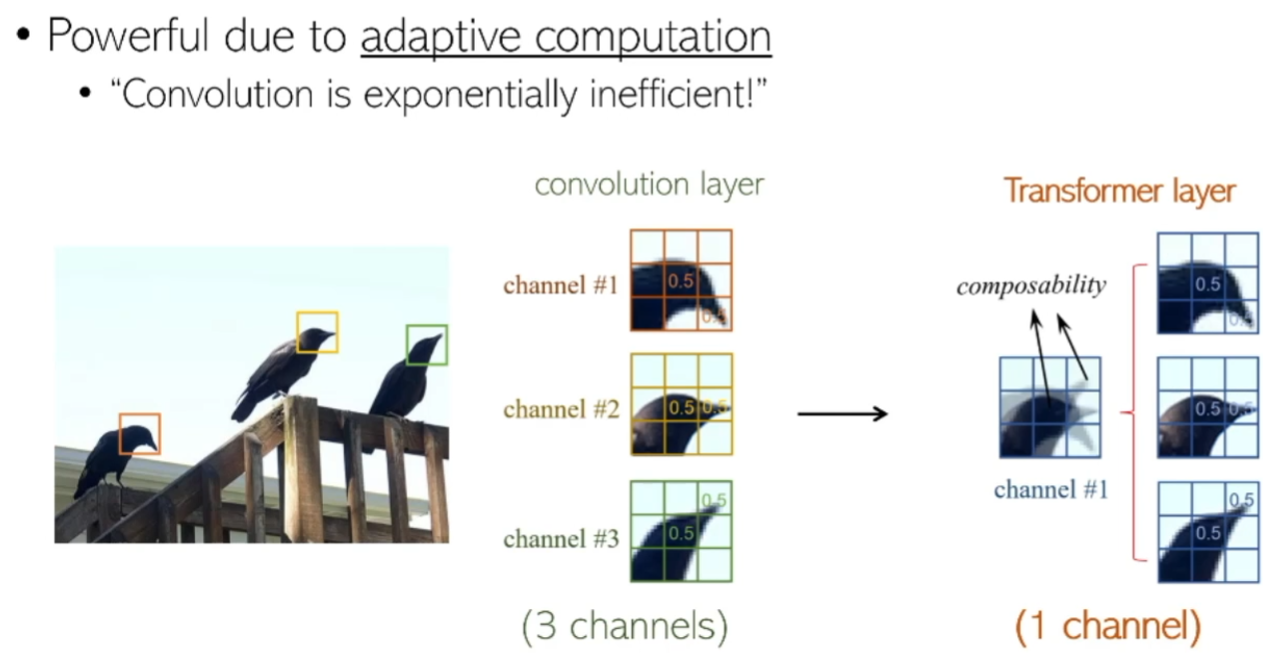
或许随着算力的提升,会有那么一天,在计算机上算一个 ViT 和今天算一个 k 近邻一样容易。
-
计图研讨会:Swin Transformer 和在计算机视觉中拥抱 Transformer 的五个理由 https://www.bilibili.com/video/BV1fr4y1e7th ↩